PeerCache¶
Peer-to-peer RDMA zero-copy L3 KV-cache backend for SGLang HiCache.
PeerCache gives you Mooncake-style RDMA zero-copy KV-cache sharing across nodes,
but without the centralized master + metadata services. It is built for
PD-disaggregated (prefill/decode) SGLang inference: prefill workers publish KV
pages, and decode workers read them back over RDMA with zero CPU copies.
flowchart LR
subgraph W["Node W · prefill / writer (hosts embedded meta)"]
direction TB
META(["Embedded discovery<br/>register · heartbeat · members"])
PW[("Published pool MR<br/>source of READ")]
DW["Directory shard"]
end
subgraph R["Node R · decode / reader"]
direction TB
RECV[("Host KV buffer · recv MR<br/>destination of READ")]
DR["Directory shard"]
end
R -. "register / heartbeat" .-> META
W -- "set: PUT key→loc" --> DR
R -- "get: GET key→loc" --> DR
PW == "one-sided RDMA READ (zero copy)" ==> RECV
classDef mr fill:#e8eaf6,stroke:#3f51b5,color:#1a237e;
classDef dir fill:#fff3e0,stroke:#fb8c00,color:#e65100;
classDef disc fill:#e0f2f1,stroke:#00897b,color:#004d40;
class PW,RECV mr
class DW,DR dir
class META discThe directory is sharded across every node (here the example key is owned by
Node R's shard); each node also hosts a shard of its own. Discovery is embedded
and multi-master — every host runs it, the discovery_addr head is pinned, and up
to max_masters (default 3) are active — so there is no separate meta process and
no single point of failure.
Why PeerCache?¶
| Mooncake | PeerCache | |
|---|---|---|
| metadata | central master + metadata service | sharded directory (consistent hash) |
| data placement | dedicated managed pool | stays on the producing node |
| coordination | master allocates / tracks objects | only service discovery, embedded in a node |
| transfer | RDMA zero-copy | RDMA zero-copy (one-sided READ) |
PeerCache is a decentralized prefix/KV-reuse cache — not a PD transfer engine. See Positioning & comparison for where it fits, the trade-offs vs. centralized stores, and when to prefer something else.
Performance at a glance¶
Measured cross-host on RDMA (GET, MLA; 2× AMD EPYC 9K84 + 8× ConnectX-7, RoCEv2, MTU 4096):
| scenario | GET throughput |
|---|---|
| single NIC, PeerCache | 46.0 GB/s — ~94% of bare ib_read_bw (49.0 GB/s) |
| single process, 8 rails (1 MiB pages) | 147.6 GB/s (1.18 Tbps) |
| full machine, 8 NICs, multi-process | 413.1 GB/s (≈ 3.3 Tbps) |
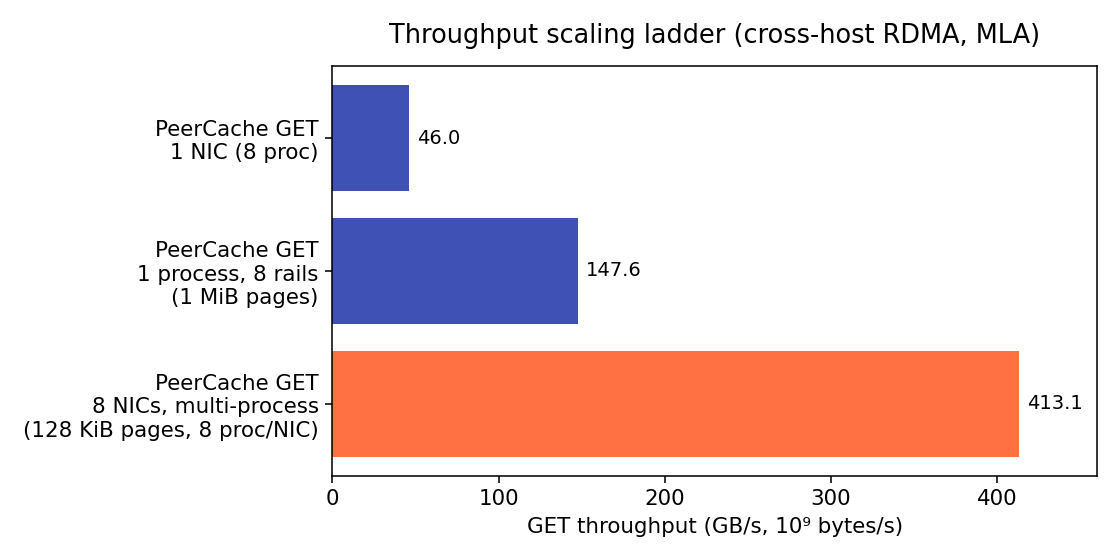
See the Performance baseline for charts, methodology, and reproduce commands.
Core ideas¶
- Embedded multi-master discovery, no separate meta node — you still set
discovery_addrto a single headhost:port(the bootstrap anchor). Every host runs the discovery service in-process; the head is pinned as the primary master, and as nodes join the next hosts are promoted in order to fill up tomax_masters(default 3). A dead non-head master is replaced automatically, and a small cluster has all hosts as masters — no single point of failure for running nodes. Nodes register, heartbeat, and pull the live membership list. No data and no metadata live there. - Consistent-hash directory (DHT) — the mapping
key -> {data_node, remote_addr, rkey, length}is sharded across all nodes by hashing the key. - Data stays local on write —
set()copies the page into a node-local published pool (a host memcpy, no network, no master) and pushes only a tiny location record to the directory. - One-sided RDMA READ on read —
get()looks up the directory, then issues a zero-copyIBV_WR_RDMA_READstraight into SGLang's registered host buffer. - Disk persistence tier (L4) — pages evicted from memory spill to disk
(default
/data/peercache/,100GB) and are promoted back into the pool on a later read, locally or by a remote reader. - Built-in monitoring — a Prometheus
/metricsendpoint plus an embedded HTML dashboard (default port31997): hit rate, throughput, latency p50/p99, memory/disk usage, and more.
Next steps¶
- Getting Started — install and run with SGLang.
- Architecture — the two-MR model, the directory, and the read/write data flows.
- SDK Reference — the Python and C++ APIs you can build on.